Tumbling, Part Three: Stochastic Spread
29 Jun 2011 No SIRSo having written the previous posts, I was wondering if this spread could be modeled. We could use the SIR equations, but this runs into the problems I mentioned before - i.e. it assumes regular infection rate, approximately uniform population distribution, etc - and as the graphs showed, this is not the case with Tumblr (or Twitter, for that matter).
There are, in fact, modifications to the SIR model to make it work with irregular population distributions. But I'm not entirely familiar with these, so I'm kinda going my own way with it and hoping for the best.
I should point out that, while SIR models are typically time linked, in this case we're working in 'spread over eccentricity' (as discussed in Part 1). The effect of this is that the model won't reflect real-time spread, but rather how wide and far from the source it goes.
Scattered Clusters
The majority of users will have between ~100-200 followers. The numbers of 'leaders' then decreases exponentially as the follower counts get bigger - with very few users having follower numbers in the thousands. Or so I'm choosing to assume; I have no data to support this.
So for this model, the users' follower counts are generated randomly using a log-normal distribution. This seems like the most plausible fit for the real-world.
For the implementation of the model, all users are generated prior to the actual spread simulation - creating a 'user pool' of the entire population (size N). Users are then randomly select from this pool as and when needed.
Pre-generating the users creates consistency, and makes it easier to keep track of who has already seen the post - assigning a new property to each user, user.exposed, which equals 1 if they have seen the post, and 0 otherwise.
Model Mechanics
You can download the code for the completed model here (Python)
So the basics of the model work like this:

a) Select F users at random from the 'user pool'
Then, for each user:
i) Has that user already seen the post?
If no,
ii) How does the user react to the post?
Ignore, like, reblog? Increment counters accordingly.
This bit of code is essentially the same as that discussed in Part 2 - using the 'per-person' approach. We also introduce a new counter, eReblog, which keeps track of the (cumulative) number of reblogs at each level of eccentricity.
iii) If a user reblogs, add their follower count to the 'follower counter' (fi)
This is something of a corner-cutting method - the follower counts for all reblogging users are mixed into the same counter. Since some of the follower groups might overlap, users are selected from the pool with replacement to compensate.
This method is perfectly fine, so long as we don't want to create graphs of who reblogs who. And for simplicity, we don't.
b) If fi = 0, end simulation. Else, go back to (a) with F = fi
Termination condition - obviously, if no-one reblogs the post, there's no need to go any further.
That's basically it.
Initial Conditions
Population = 3,000; F0 = 150, Threshold Ranges: [4,11], Post Quality: No(3,2), Followers: Log-No(5,2)
Obviously, the population of Tumblr is much larger than 3,000. But this code starts to struggle when you get into the 10,000s, so if we're too impatient to wait much more than a minute for results, we have to make concessions . Not that that should have significant effect, other than the population being exhausted quicker.
The post quality has been set low, and the thresholds high, so that the spread doesn't instantly explode and burn out. This makes the results more interesting to observe.
Reassuring Results
Below is a graph of seven example outputs of the model - ALL with the same initial conditions.

In particular, I like 'Row 8' (dark purple) - the way it stays fairly low, then has a sudden burst at generation 4 - similar to what happened with the Dr Who image in Part 1 (albeit with only one burst).
We also have, in 'Row 2' (red) a spread that starts to die out immediately, as with the HIMYM image (also mentioned previously).
One result not graphed, because it can't be, was an example outcome where the post didn't spread at all (ie 0 reblogs) - which is not an uncommon occurrence in the real world.
While we're at it, here is graph for the average of all the lines in the previous image
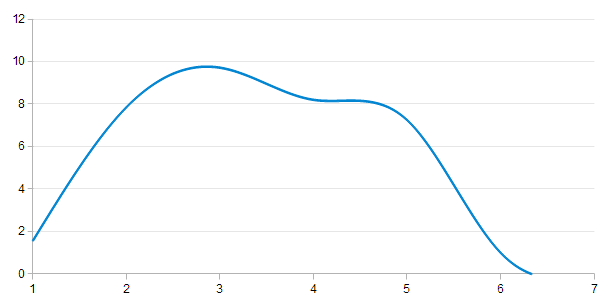
For comparison, here is what the graph looks like when the post quality is higher, and the approval threshold on a wider range

Shape-wise, these graphs don't seem to differ significantly from those you'd expect to see from a SIR model. Not identical - there's certainly much more variance from this model - but it's interesting to see all the same.
Finally, if OP is 'Tumblr Famous' - that is, has 1,000 or more followers - this model would seem to suggest that their larger follower count has little effect on how far a post (subject to our initial conditions) would spread. This seems strange.
That being said, if we're using a population size = 3,000 , then an OP starting with 1,000 followers means that a third of the population is exposed and used up right away. So further investigation is probably needed on that one.
Notes and Improvements
So this model works, and is pretty good. But it's by no means perfect.
1) The Problem With Approval
Behaviour of super-node may vary from that of normal people - eg more exclusive, selective, etc - but for simplicity, this is ignored. That said, if true it wouldn't be too hard to have approval thresholds dependent on, for example, follower count.
2) Reblogs From Tags
Some people discover via their tags - or for that matter, through search engines - rather than from the people they follow. If we were desperate to incorporate this into the model, it could be as straight forward as picking extra (unexposed) users when choosing from the user pool.
3) Didn't See It
Some people just don't see the post, or don't see it til much later and from someone else. But we can assume that the former are indistinguishable from those who did and ignored, and can ignore the latter.
4) Who Reblogged Who
We'd have to replace the part of code where the reblogs are grouped into a single counter with code that has some sort awareness of who each user reblogged - see Appendix I
And while we're at it, we could also build up a graph off how all these users are connected - ie, a who follows who graph. But that's not necessary.
5) Fine-Tuning
For this model I chose the random distributions and variables arbitrarily, but based on educated guessing. Obviously, this is not ideal. For the best model, we'd need to tweak these to closely match real-world data. Sadly, I don't know where this data would come from.
What Use Is This Anyway?
The thing is, the advantage of the SIR models is that they can be solved exactly when looking for stationary points, or what initial conditions would lead to an epidemic, etc.
This is not the case with our stochastic model. Instead, we're left having to just play with the variables and observe the resulting behaviour. We could also modify the code to allow predefined variables to remove some of the randomness.
One other way the model could be used is, for a fixed set of initial conditions, repeat the simulation a significantly large number of times and look for the most likely outcome, as per the Monte Carlo method.
And as mentioned above, a similar model can be used to model spread of information through any network - including Twitter. It's just a matter of tweaking variables.
Anyway, the model serves its purpose as is, and I'm pleased with it. So yeah.
Oatzy