Follow Up: Will I Get a Table?
17 Jan 2011 So the model I talked about last time is all well and good, but you might find yourself thinking, "well what good does it do me?"It's a fair question. So here's how it works.
First of all, I made some updates to the original model; for example, people can now stay for varying amounts of time.
So what you could do is run the model as it is and look at what's happening at the time you're going to arrive. That has the benefit of it giving you some idea before you actually arrive at the café. But the drawback that it's a bit of a stab in the dark.
Instead, it's been reworked so you tell it things like how many tables there are, how many are taken, how many people are in front of you in the queue, etc.
Anything you can't directly count, the code basically guesses.
Guessing?
It's a sort of educated guessing. You can measure 'global' things, like how long people typically stay, and you'll get some sort of distribution of times. So what the code basically does is make guesses based on that observation.
If you run the model once, you get one possible outcome - what might happen.
But if instead you run the model, say, 1,000 times, you can work out what percent of those possible outcomes have at least one table unoccupied. And from that you get a decent estimation of your odds of getting a table without having to stand up, waiting, first.
Obviously, it you run it for more cycles (say 10,000) then the output will be more 'accurate'. But at 1,000 cycles you get a variation in results of about 5%, which is acceptable, and it's less processor intensive.
The other thing I had it do was take an average to get an idea of, approximately how many tables will be free (before you sit down) and how long you'll be queuing.
Just to give you an idea, the output looks like this

It also assumes that the staff don't (significantly) vary in how many people they can serve in a given period of time.
Opportunism
I mentioned last time the fact that groups of people will usually have one person standing in line while the others find a table. First of all, I managed to implement it in the model.
But second, and more interesting, if we assume everyone is about equally opportunistic, then your odds of getting a table are about the same as if everyone waited until they'd been served before looking for a table.
Obviously, if you were the only one being opportunistic then you're odds would go up (at least a little), and conversely, if you were the only one not being opportunistic, then that would put you at a disadvantage.
For the shear hell of it, here's a pay-off grid for the different strategies,
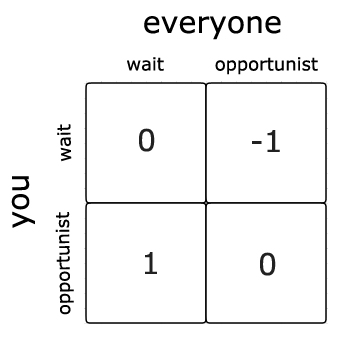
Although this is only really a problem if tables are limited.
Usefulness
Well first of all, the accuracy of the results is going to be dependent on the global variables, like rate of service, typical stay time, etc.
Secondly, the output is mostly intellectual; that is, the output is unlikely to affect your behaviour*, and nor will it explicitly help you get a table. But it's interesting to look at.
And as said above, in terms of ensuring you'll get a table, the strategy for when tables are limited is to grab a table as soon as you see one free up; and hopefully before anyone else can get to it.
But all that aside, the code is here for if you want to have a play.
Oatzy.
* if you're at the back of 12 people and the model gives you a 5% of getting a table, you might be tempted to go somewhere else, or come back later.