Model Café
09 Jan 2011 Reading Simple Complexity gave me the want to create a simple simulation of a real world system.And for whatever reason, I chose a Café. In fact, I was thinking about this around Christmas, and noticed that no matter how busy or how full it got in Costa, there never seemed to be anyone standing around waiting for a table.
Which when you think about it is a little odd. I had some theories, but mostly I just wanted to prove that I could write a simulation.
The Model
I wrote the code for this in objected-oriented style. That fact isn't entirely important or relevant, it's just an approach I like to use sometimes.
So the model works along these lines

Basically, a person will be in one of three 'objects' - queuing, waiting for a table, or seated (the big boxes above).
And you can track things like how many people are queuing or waiting and for how long, how many tables are in use or available.. And from these you can get an idea of how things work and what you can potentially do to improve how smoothly things run.
You then have processes that manipulate these objects. The whole process runs in fixed time chunks; in this case five minutes. So in a given chunk what happens is:
1) anyone who's been seated for a certain amount of time (st), leaves
2) anyone who's been served and is waiting looks for a table
3) more people arrive (P(t)) and join the back of the queue
4) a certain number of people (tp) are served
5) if there are tables available, they're seated. Anyone who can't be seated joins 'waiting'
Poisson
Say you work a 3 hour shift at a shop, and in that time you serve 54 people. You served, on average, 3 people every 10 minutes. But people don't arrive so evenly spread out - in any given 10 minutes you won't necessarily get 3 customers. Instead, people tend to show up in clumps. So in one 10 minute chunk you might get no customers, in another you might get 5 customers, etc.
The Poisson Distribution is a probability distribution that gives the probability that you'll get, say, 5 customers or 3 customers or whatever in a given 10 minute chunk (given that you expect to get, on average, 3 per 10 mins).
So for this model, P(t) - the number of customers arriving in a given time chunk - is a function that spits out a random whole number between 0 and 6, based on a Poisson distribution. The other thing I did was to make the average variable over the course of a day - i.e. you're likely to get more customers around lunchtime.
There's actually an area of applied maths called Queuing Theory. And there's a good video introducing the subject - Why the Other Line is Likely to Move Faster - by Bill 'engineer guy' Hammack, which I would recommend.
Variables & Assumptions
So you have some random number of people arriving at each interval. Your other variables are,
- Number of tables; n
- How long people stay; st ~ 25mins
- How many customers are served per 5 minutes (through-put); tp = 2 to 3
The assumptions are that customers arrive on their own and sit one to a table. That it takes the same amount of time to serve each customer, and that every customer stays the same amount of time (values above).
Obviously, these things do vary, but some things are better kept constant, or else things just get needlessly complicated and erratic. And omitting variation in these variables shouldn't significantly affect the output.
Results
So here's an example of the output
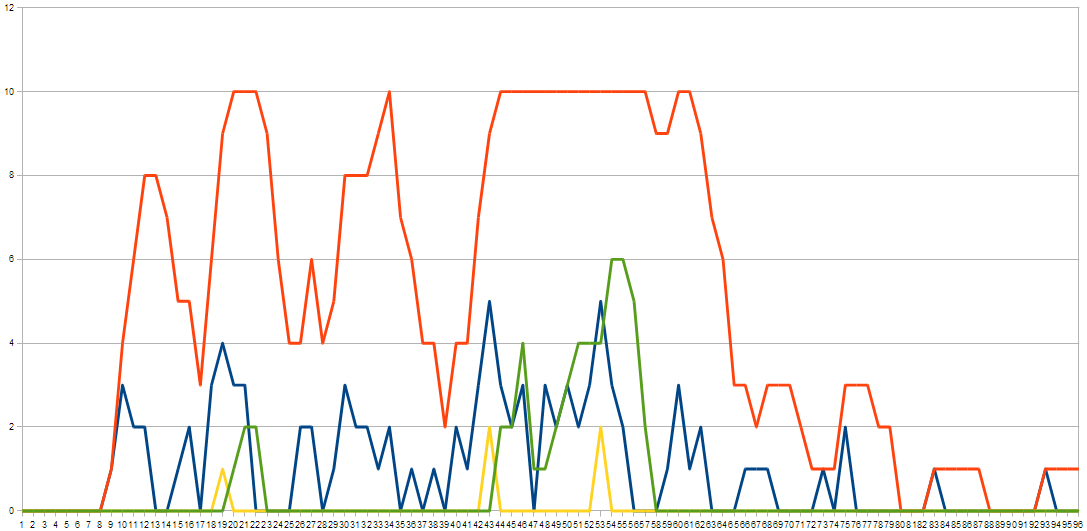
The model works in 5 minute chunks, for 96 chunks - approximately one day, 9am to 5pm; 10 tables, st=5, tp = 3.
The orange line is the number of tables in use. The blue line is people queuing at the start of the 5 minutes (after the new people have arrived, and the yellow line is at the end of the five minutes (after people have been served). And the green line is the number of people who have been served and a are waiting for a table.
And over all, it looks a little chaotic. There certainly doesn't seem to be any patterns or logic in any of it.
Another way you can visualise the output - and this really is mostly just for the sake of a different approach - is to use a heatmap (made in R). Here are a couple
Both with the same input variables.
Each column represents 10 tables for a 5 minute chunk. Again, the whole thing is for the course of a day. if a square is white in a given column, then that table is empty in that given time chunk. If it's blue, that table is in use; the darkness of the blue indicates how long the person's been sat at that table. And if you count the white squares down the column you get how many tables are available/in use.
As I say, it's pretty, and it's an alternate way of visualising the output. But it's not necessarily useful. An animated one would probably have been better, but that's still beyond me.
Insights
What insights do you get from this model? If you play around with the variables, you start to notice patterns.
First of all, the most important part of the model is how fast the customers are served. For example, if they serve too slowly then a huge queue with a long waiting times will quickly form, and that's hardly ideal. But conversely, if there are a lot of customers coming in, and if they serve too quickly, the tables soon fill up, and you're left with people standing with a tray of drinks, waiting for a table to free up.
In fact, what you find is that the maximum number of tables you need (so that no one is ever waiting) is equal to the average number of people served during the average amount of time a person stays.
So, for example, if people stays for, on average, 25 minutes, and the staff serve up to 3 people every 5 minutes, then you would need a maximum 15 tables.
But what this also means, is if you have a certain number of tables, and they're (almost) all full, you can limit the number of people waiting for a table by serving SLOWER. It sounds odd, but generally, people would prefer waiting a little longer to be served, than standing around with their drink going cold, waiting for somewhere to sit.
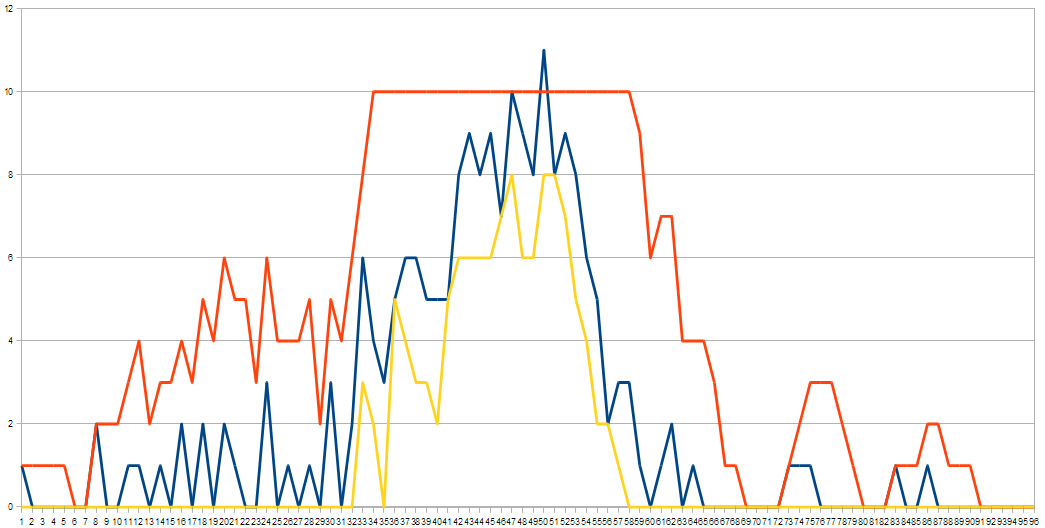
And you can demonstrate this with the model, by varying the through-put. In the above, you have a lower through-put and no-one waiting. But unfortunately the bottle-neck also means the queue gets quite long as a side-effect.
So instead you can set a maximum through-put, but when tables are limited, this number drops. And when you do this, you find that you can (almost) entirely eliminate 'waiting'. But more importantly, because the through-put isn't just set arbitrarily low - because it can increase up to some max when it's less busy - you also limit the effect this slowing has on queue size and queue waiting time.
And this is essentially the key to keeping everything in the (model) café flowing as smoothly as possible. And this is one potential explanation for why I never saw people waiting for a table.
Two's Company
Now in the real world, people don't always show up on their own. They might come with their friend, they could come in a group of five, or whatever. The question is, how would this affect the model?
Well if you treat the group as a 'packet' then you can introduce them to the queue in packets, and again it's typically one packet to a table - assuming the size of the table has negligible effect, since when tables are limited, opportunism out-weights getting a table of the 'right size'. We can also assume that being in a group doesn't have too much effect on how long they stay.
So the only significant effect groups have on the model is that the larger order takes longer to process - it affects the time required to serve one 'packet', so affects the through-put.
But, in fact, what this means for the system is that it's the naturally occurring equivalent of varying the speed at which people are served; for example, serving a group of three will take about as long as serving a single person at a third of the speed.
So this is another possible explanation - groups cause natural, variable bottle-necks that control flow, and therefore tables needed.
Modifying the model, the results seem to support this idea. Sometimes.

You do still get people waiting, but it certainly seems reduced. Of course, the other side effect is that the queues (and waiting times) often get longer. But that is, to a certain extent, to be expected and unavoidable.
Other Factors
When it gets busy, people get opportunistic and if they're in a group of two or more, then one person will wait to be served while the others grab the first table they find. This is hard to model for, but we assume it's effect is negligible.
When it gets busy, people will do one of three things:
1) wait in line and hope they can get a table
2) stay in line, but get the drink to take out
3) if the queue is significantly long when they arrive they might just leave (possibly coming back later).
The effect of number two is essentially to reduce the through-put, and this is kind of accounted for by the variable rate. The effect of number three is to make the queue length slightly self limiting. But you can also pretend they never joined the queue, and this is accounted for by the random arrival rate. But you could add it in if you really wanted.
Other Applications?
The basic model applies to any system with that same set up of queuing to get into an area that contains a finite number of slots, staying for some amount of time, then leaving. So cafés, restaurants, fast food places, and even car parks.
Slight alterations needed, maybe. Like for a car park, there are more spaces, but you stay longer. And if there isn't a barrier then you don't necessarily get that bottle neck (until it gets really full). But the basics of the system, and the insights gained from it 'should' apply to at least some degree.
So there you have it.
My code's here. It's messy, and the output is really designed to be simple, and useful to me, so don't expect it to spit out graphs - they were all made in 'post-production'. But if you're interested, it's there.
Oatzy.