Advent of Code 2022 was a bit of a miss for me. After getting all the stars in 2021, I didn’t have quite the same drive, and gave up after day 10. Besides which, I had something more compelling to do - making crochet Christmas ornaments.
I wasn’t sure I’d bother at all this year. I was trying to think if there was a way to spice it up - doing it in python is dull, I write python almost every day.
Then one day at work I was doing some API stuff on the command line with curl and jq, and it got me thinking…
jq
I’d wager most developers have heard of jq, the “lightweight and flexible command-line JSON processor”.
Odds are, if you’ve used it you’ve probably not done anything more exotic than picking out fields
curl localhost:8000/auth/token/ -d '{"username": "foo", "password": "bar"}' | jq .access_token
That was most of what I did. Occasionally, I’d try to do something more complex, usually with liberal help from google.
Heck, I’ve seen coworkers use jq to pretty print json, then use grep and sed to grab fields.
Anyway, it seemed like it would be fun to try and do some AoC in jq
Before we get to specific puzzles, lets look at…
General stuff
Not json
The first thing is, of course, that jq is for processing json.
On the other hand, AoC puzzles are rarely (never?) json formatted. Usually the input is lines of plain text.
A little googling tells us the way to deal with this
The -R flag means “don’t try to parse this as json”. The -n flag is needed for reasons I don’t fully understand.
Then the inputs filter is how you actually get at the input - it’s a generator of lines. Alternatively, you can do [inputs] to get an array of lines
A slight variation is when the input isn’t one-per-line, but multi-line blocks, separated by a double newline.
In that case, we don’t want the input to be split line-wise. So instead we use the -s (slurp) flag to pull in the whole input. We then get the full input with input singular and do our own splitting
... | jq -Rns 'inputs | rtrimstr("\n") | split("\n\n") | ...
rtrimstr gets rid of any trailing new line, otherwise we usually end up with an empty string somewhere down the line, which causes confusing errors
Scripts
If you’ve used jq, you’ve probably used it directly on the command line ... | jq '.[] | .count'
This is fine for simple stuff. But as things get more complex, especially when you start introducing functions, it makes more sense to put everything into a script file. The script file can then be passed to jq with the -f flag - ... | jq -f script.jq
But we can do one better - we can set a ‘shebang’
You can use the path of jq directly rather than env if you prefer. -S on env allows us to pass flags to jq
Then it’s just a matter of setting the script to executable (chmod +x), then you can invoke the scripts directly
This is what you’ll find in my solutions repo.
Functional programming
One thing I didn’t notice about jq until I started using it in earnest, is that it’s a functional programming language.
My experience with functional programming is all that passes for FP in python, and a failed attempt to learn Haskell. But I’ve picked up a few tricks along the way.
The thing that took some adjusting to is not having a for-loop, but rather having to think in terms of recursion.
Also mutation is not so straightforward. I only used it once.
Assignment
Variables can be assigned in the middle of a pipeline, for example
$ echo '[1,2,3,4,5]' | jq '(length | debug) as $l | debug | add / $l'
["DEBUG:",5]
["DEBUG:",[1,2,3,4,5]]
3
It’s not needed in that example, but you get the idea. It allows you to perform some calculation on the current value and capture that into a variable. It then passes along the original current value unchanged.
This is convenient if a value needs to be reused, or just to make the code more readable
Debugging
The errors from jq tend to be terse, and often not that helpful.
In this case, it’s useful to throw in some debug statements
$ printf "1\n2\n3\n" | jq -Rn 'inputs | debug | tonumber'
["DEBUG:","1"]
1
["DEBUG:","2"]
2
["DEBUG:","3"]
3
Yes, this is akin to putting print statements everywhere. You work with what you’ve got :)
Basically, it prints out the input value then passes the input along unchanged.
There’s a variation where you can pass it a message e.g. debug("hello") but that isn’t supported in the version installed on my laptop.
Documentation
The manual is a bit hit and miss.
For example, the search box is more like ‘jump to heading’
I wanted to find a way to sum an array of numbers, so I searched sum, no match. total, no match. I knew about reduce so I implemented sum with that. Then I was scrolling through the docs looking for something else and spotted add, which was exactly what I had wanted : |
Long story short, Ctrl+F and google are your friends.
As far as I can find, there’s no standard formatter in the vein of black, gofmt, prettier for jq
So for my scripts I had to go with what felt right to me.
The Puzzles
For part 1 we need to pick out the first and last digit from a string, the wrinkle being there may be only one digit present.
Regular expressions are the obvious choice for this task - scan("\\d") - returns an array of digits (strings), from which we can grab the first .[0] and last .[-1] (or indeed ‘first’ and ‘last’)
For part 2, we also have to account for digits written out as letters, and the ‘obvious’ solution is to string replace words for digits, at which point the rest of the solution is the same as for part 1.
The tricky bit is that digit names may overlap, e.g. in eightwothree ‘eight’ is the first digit name, but if we substitute digit names in numerical order, we’d replace ‘two’ to get eigh2three, losing ‘eight’
To workaround this, I had a sudden flash of inspiration while brushing my teeth (as one often does) - what if we substitute the digit numeral, wrapped in its name.
For example we replace two with two2two. When we do that in the example, we get eightwo2twothree. Now we haven’t lost ‘eight’.
The final piece (arguably unnecessary) is solving both parts in one.
As noted, after transforming the input for part 2, it’s solved in the same way as part 1
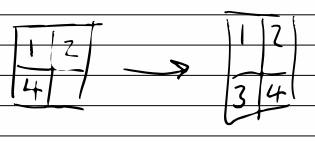
So for each line, we create an array of [., sub_numbers] ([part1, part2]), find digits, and transpose from
[[line1-part1, line1-part2], [line2-part1, line2-part2], ...]
into
[[line1-part1, line2-part1, ...], [line1-part2, line2-part2, ...]]
then sum up each part.
This transpose trick comes up often.
This one looks hard at first glance. The trick is parsing it, with regex and lots of splitting, into the right structure
The key bit is getting an array of [colour, count] pairs into a mapping (object) of {colour: count} using from_entries
Once you have that, the actual solution is straightforward, just applying a couple of functions.
An observation which makes this one easier - any given number will only appear once on either side of the |, so we just parse all the numbers in a line into a single array, group the numbers together, then look for the ones there are two of.
$ echo '[1,2,3,4,2,5,1]' | jq -c 'group_by(.) | debug | map(length)'
["DEBUG:",[[1,1],[2,2],[3],[4],[5]]]
[2,2,1,1,1]
(-c means compact format; otherwise the result would be pretty-printed/split across multiple lines)
Part 2 was more interesting. We start with a list of (wins, count) for each ticket. For each ticket we add count to the wins number of subsequent tickets, then return the number of this ticket plus a recursive call, e.g.
r([(2,1), (1,1), (0,1)])
= 1 + r([(1, 1+1), (0, 1+1])
= 1 + 2 + r([(0, 2+2)])
= 1 + 2 + 4
= 7
This is another one I didn’t think I could do. But again, once you get past parsing the input it’s a lot clearer.
Then it’s just raw calculation.
I didn’t manage to solve part 2. I did try, but my solution didn’t scale.
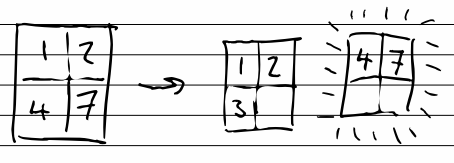
But while we’re on the subject, surprisingly difficult was splitting an array into chunks; I’m surprised there isn’t a built in for it.
The solution I came up with was a sliding window using foreach, which emits the current pair every other iteration.
echo '[1,2,3,4,5,6]' | jq -c 'foreach .[] as $i ([0, null, null]; [.[0] + 1, .[2], $i]; debug | if .[0] % 2 == 1 then ("skipped" | debug | empty) else .[1:] end)'
["DEBUG:",[1,null,1]]
["DEBUG:","skipped"]
["DEBUG:",[2,1,2]]
[1,2]
["DEBUG:",[3,2,3]]
["DEBUG:","skipped"]
["DEBUG:",[4,3,4]]
[3,4]
["DEBUG:",[5,4,5]]
["DEBUG:","skipped"]
["DEBUG:",[6,5,6]]
[5,6]
If you write out the formula for distance vs time, what we want to find is (T - x) * x > D or x^2 - Tx + D < 0
In other words, it’s a quadratic equation (inequation?), and we want to find the integer values of x which give a value less 0, which we can get with the quadratic formula
T - sqrt(T^2 - 4D) T + sqrt(T^2 - 4D)
------------------ < x < ------------------
2 2
To get the count, we take the difference of (the floor of the larger value) and (the ceil of the smaller value), plus one. There’s an edge case where this doesn’t work, when the bounds themselves are integers, as is the case with one of the examples.
But that wasn’t the case in any of my puzzle inputs, so I ignored it :D
My first thought, taking inspiration from day 4, was to ‘quantify’ each hand using group_by and length. But how to order them? I wrote out the possibilities
5
4,1
3,2
3,1,1
2,2,1
2,1,1,1
1,1,1,1,1
These are all the ways to partition 5 (not counting permutations). Not that that helps here. But it occurred to me, if I pad them with 0 until they’re all length 5, then they sort in the right order, i.e. 50000 > 41000 > 32000 > 31100, etc
But what about the values of the cards themselves? As they are, they’re not sortable because e.g. king is higher valued than queen, but K is less than Q lexically.
The dumb solution I came up with was to translate the face cards into their equivalent hex value, i.e. T -> A, J -> B, etc.
We then concatenate the hand type with the hexified cards to get a ‘canonical’ form, e.g.
32T3K -> 2111032A3D
T55J5 -> 31100A55B5
KK677 -> 22100DD677
KTJJT -> 22100DABBA
QQQJA -> 31100CCCBE
Then finding out the ‘power’ ordering is a simple lexical sort
For part 2, we count the Js, quantify the hand without them, then add the J count to the largest of the remaining groups, e.g.
KTJJT - > 2 + KTT -> 2 + (2,1) -> (4,1)
and when converting to hex we replace J with 1 instead of B
Then the rest works the same as part 1
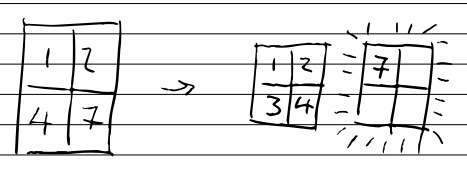
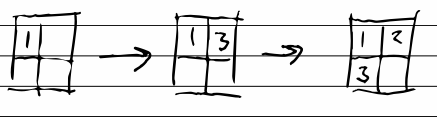
pad is another function which is surprisingly absent from jq. Additionally, the repeat method is unbounded. So I used range + foreach to generate an array of 5 zeros, then zipped (transposed) that with the input, which pads the input with null
$ echo '[1,2,3]' | jq -c '[., [foreach range(5) as $i (0; .)]] | debug | transpose'
["DEBUG:",[[1,2,3],[0,0,0,0,0]]]
[[1,0],[2,0],[3,0],[null,0],[null,0]]
then use max to take advantage of the fact null is less than any other value.
Part 1 is a fairly straightforward parsing of a tree structure into an object - from_entries is our friend - then a recursive walk for the length.
Part 2 is a classic AoC trap. You try to play it out, then realise it’s going to take forever for it to complete executing that way, and actually the different paths are looping, so you just need to find when the loops coincide.
For that we need to calculate the lowest common multiple of the loop lengths, and to my great shame I had to look up the formula on wikipedia (probably the last time I did an LCM was AoC 2021).
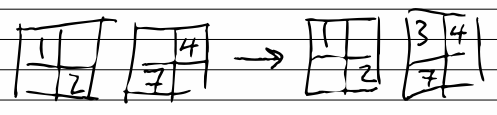
To get the pair-wise difference, we ‘zip’ the input with itself offset by one
$ echo '[1,2,3,4,5]' | jq -c '[.[:-1], .[1:]] | debug | transpose'
["DEBUG:",[[1,2,3,4],[2,3,4,5]]]
[[1,2],[2,3],[3,4],[4,5]]
Otherwise it’s just implementing the procedure as described in the puzzle.
This one I did by brute force - that is, replace each ? with a # or . and see if it matches the pattern.
It was slow - took something like 10mins - but it got there in the end. And more to the point, it was easy to implement.
It did not, however, scale for part 2. I didn’t even bother trying, given how long part 1 took.
For this, finding the horizontal reflections didn’t seem too bad - slice each line, does the first half match the reverse of the second half.
But what about vertical reflection?
Then I remembered the trusty transpose function, which turns the vertical problem into the horizontal problem again. Easy.
Part 2, not so much.
For this we have the handy explode function, which turns a string into an array of ‘code points’, which are conveniently the same as ASCII values (yay, unicode)
Finding where (and when) the paths collide can be found algebraically.
Having said that, translating said algebraic solution into jq was horrendous. Seriously, that script should come with a content warning :p
jq-wise, we have the convenient combinations function to generate all the pairs of hailstones. You just need to remove self-pairs and reverse pairs
$ echo '[1,2]' | jq -c '[. ,.] | combinations'
[1,1]
[1,2]
[2,1]
[2,2]
i.e. [1,1] is a number paired with itself, and [1,2] and [2,1] are the same just in opposite orders.
Conclusion
Well, it was fun while it lasted. Given jq is Turing complete [citation needed], it is theoretically possible to solve all the days with jq, but I’m afraid that’s beyond my skills/determination.
In the end, I got 19 out of 50 stars (38%), which I’m pretty sure is a failing grade. Oh well :)
The sad thing is, having learned all this jq, I’ll probably never use it professionally. Anything which requires more complex jq processing than what will fit on a single line would just raise the question - why not write it in python instead? After all, python is more readable and more testable.
To that point, as I was writing this blog I was looking back at my solutions and thinking, “erm.. how does this work again?”
Still, a fine way to pass the time before Christmas.
Chris.
[And I did also find the time to crochet more Christmas decorations]
]]>














.jpg){kind=link}
{kind=link}